Chapter 3 Genomic libraries and sequence capture
Genomic DNA was extracted from 5 mg of dried leaf tissue with a CTAB protocol (Doyle & Doyle 1987). DNA extracts were digested with ‘Ultra II FS Enzyme Mix’ (new England Biolabs Inc, MA, USA) for a target size of 150 bp, and libraries built with the ‘NEBNext Ultra II FS DNA Library Prep kit for Illumina’(New England Biolabs Inc, MA, USA). We amplified and tagged libraries using 5 \(\mu L\) of adaptor-ligated DNA, 8.3 \(\mu L\) of ‘NEBNext Ultra II Q5 Master Mix’ (new England Biolabs Inc, MA, USA), 2x 1.6 \(\mu L\) of Index Primer i5 and i7 from ‘NEBNext Multiplex Oligos for Illumina (Dual Index Primers Set 1 and Set 2)’ (new England Biolabs Inc, MA, USA). Initial denaturation (98°C for 30 s) was followed by 8 cycles (98°C for 10 s and 65°C for 1 min 30 s) and a final extension (65°C for 5 min). We pooled libraries in four equimolar multiplexes for each genus. We obtained a custom made set of 20,000 80-mer probes using myBaits Custom 1-20K (Arbor Biosciences, MI, USA) and conducted the capture experiments using the corresponding myBaits V4 protocol with a hybridization time of 80 hours. We pooled the four multiplexes and sequenced them in two lanes of an Illumina HiSeq 4000 instrument obtaining 2x150bp pair-end reads.
3.1 Plates
This sub-chapter describes preparation of plates after the extraction and before library preparation. First we looked into plates design after extraction. Then we quantified their concentration, volume and DNA quantity, before rearranging them based on their concentration. Finally plates concentration was adjusted to 20 \(ng.\mu L^{-1}\) and sorted by electrophoresis evaluation.
3.1.1 Extraction
3.1.1.1 Extraction Plates
Plates after extraction were arranged following figure 3.1.
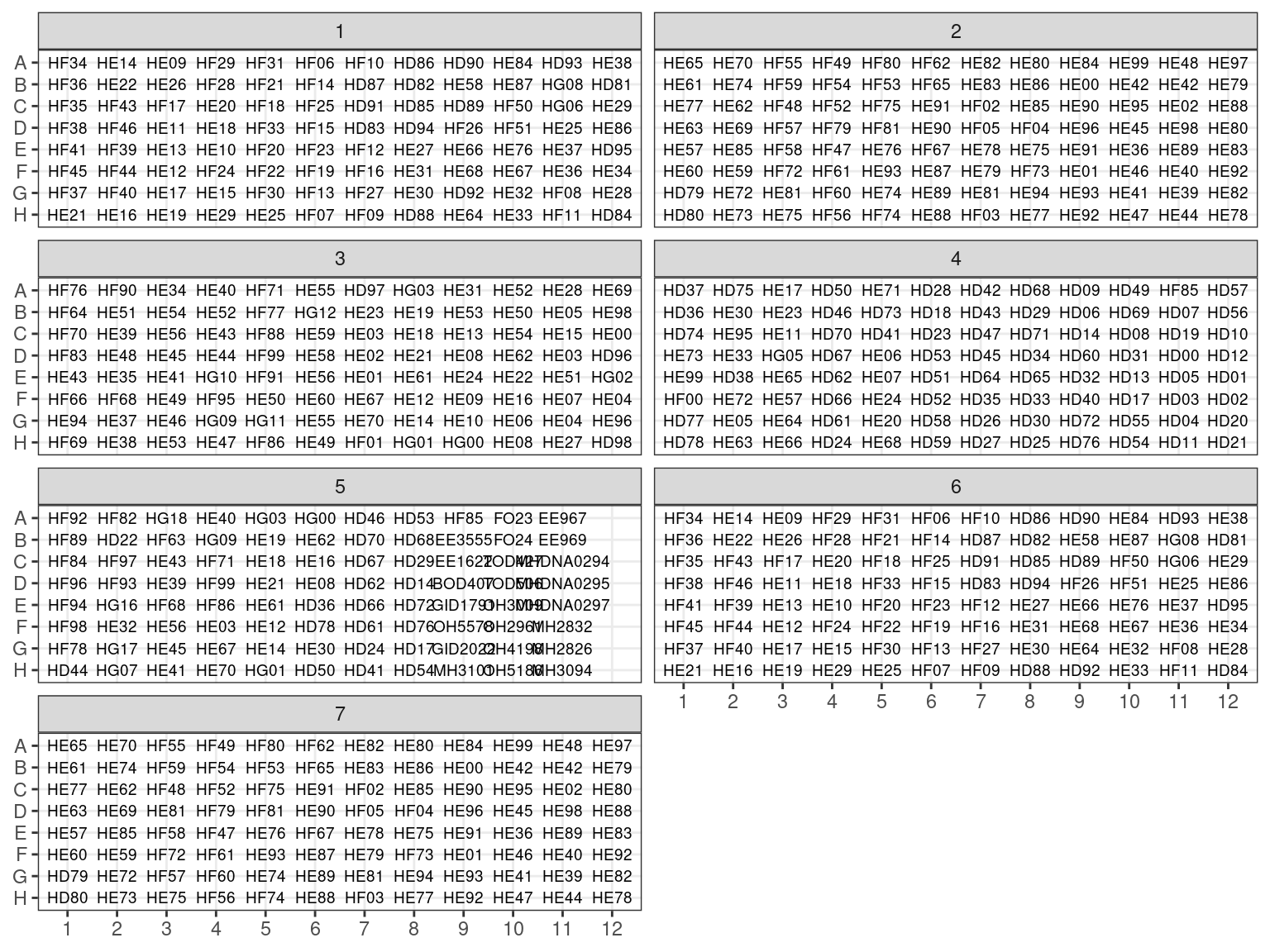
Figure 3.1: Extraction plates organization
All plates were quantified through NanoDrop and some of them with Qubit which is more accurate. We used Qubit-NanoDrop relation to have an estimation of concentration for all samples. Finally electrophoreses were also used to assess DNA quality and degradation.
3.1.1.2 Extraction NanoDrop
NanoDrop evaluated \(1 \mu L\) of samples DNA concentration (figure 3.2) by absorption in addition to contamination. But NanoDrop is known to be inaccurate, especially under 25 \(ng.\mu L^{-1}\).
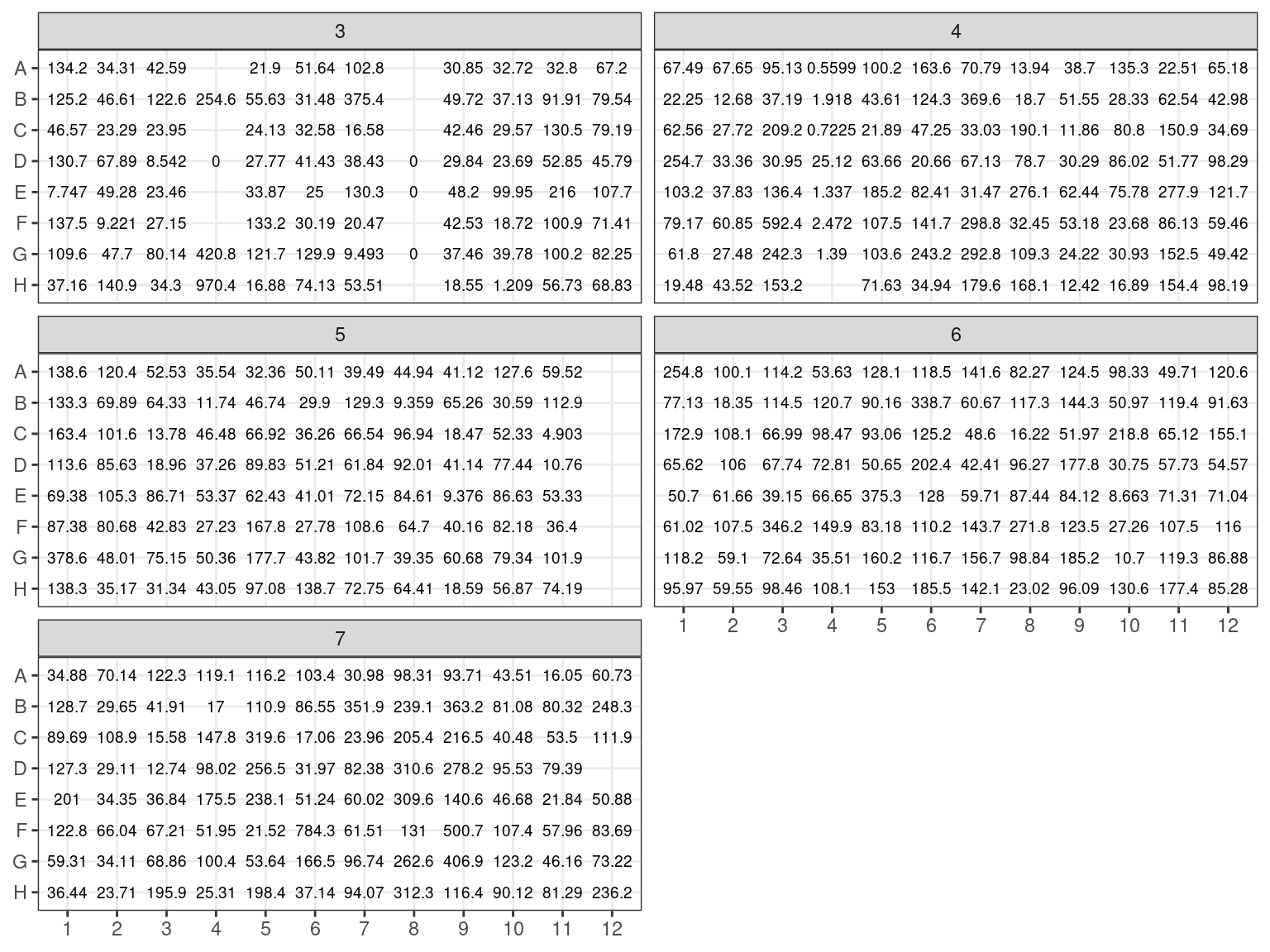
Figure 3.2: Extraction plate NanoDrop concentration (in ng/microL)
3.1.1.3 Extraction Qubit
We used Qubit on 12 samples to have a more precise idea of samples concentration. Qubit uses fluorescence to measure samples concentration in \(ng.\mu L^{-1}\). We compared Qubit estimation of concentration to NanoDrop estimation. We used a bayesian approach to fit the model \(Concentration_{Qubit} \sim \mathcal{N}(\beta*Concentration_{NanoDrop},\sigma)\) with a null intercept. We found a pretty strong relation with a beta around 0.3. We used this relation to better estimate the concentration of all samples.
| term | estimate | std.error | rhat |
|---|---|---|---|
| beta | 0.294358 | 0.0226327 | 0.9998834 |
| sigma | 7.881824 | 2.2547057 | 1.0013069 |
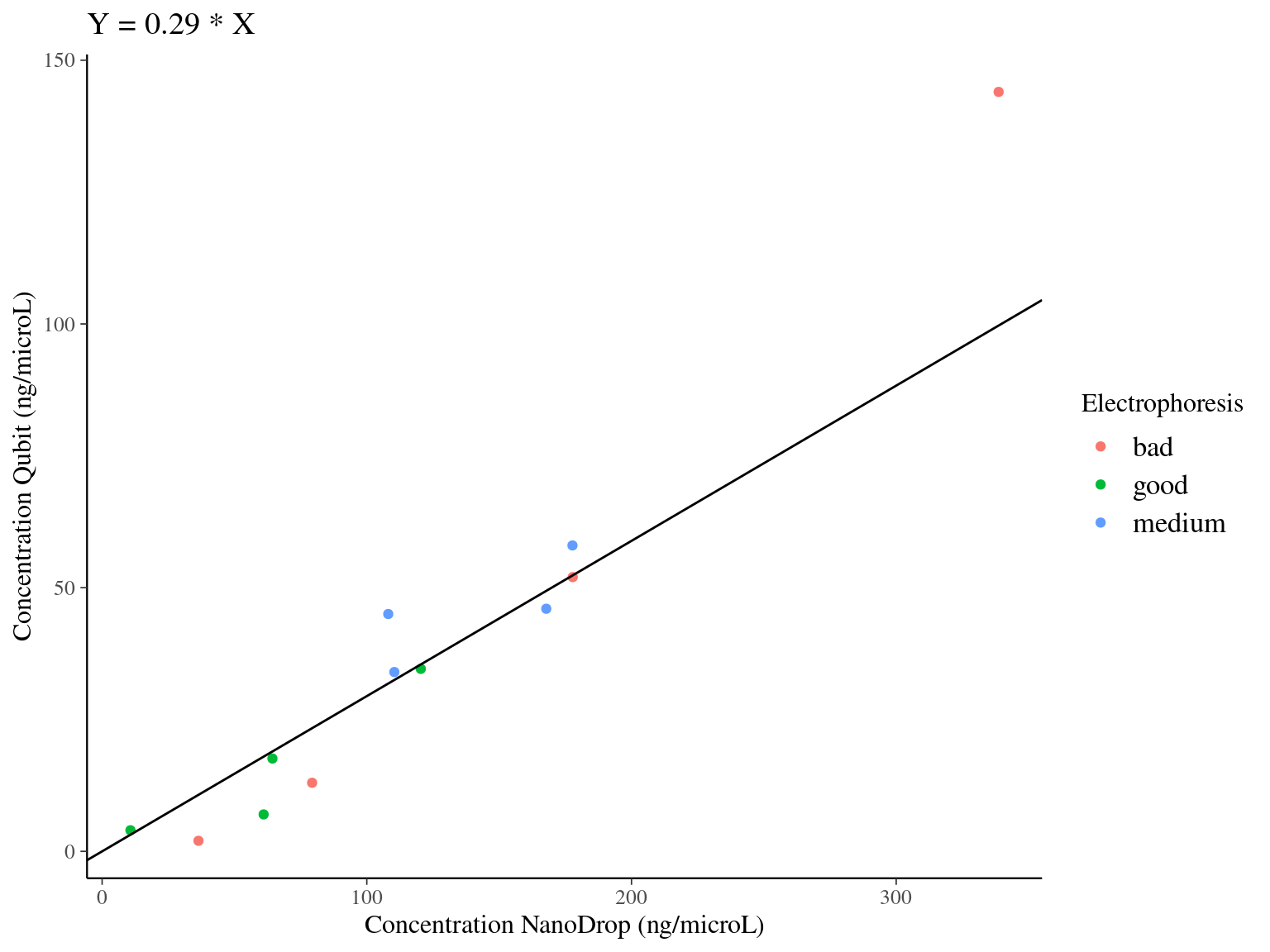
Figure 3.3: Model result of the relation between DNA concentration measured with Qubit and NanoDrop. Color indicates the electrophoresis classification of the samples.
3.1.1.4 Extraction Electrophoresis
We evaluated samples quality and degradation by an electrophoresis of 1 to 1.5 \(\mu L\) of sample DNA with 1 to 1.5 \(\mu L\) of weight migrating 20 minutes with 20 V on an agarose gel with 80 \(mL\) of 0.1 X TAE with 1 \(\mu L\) of red gel. Samples were classified as good, medium and bad. “Good” samples only included a band at high molecular weight. “Bad” samples only included a smear at low molecular weight indicating degraded DNA. “Medium” samples included both.
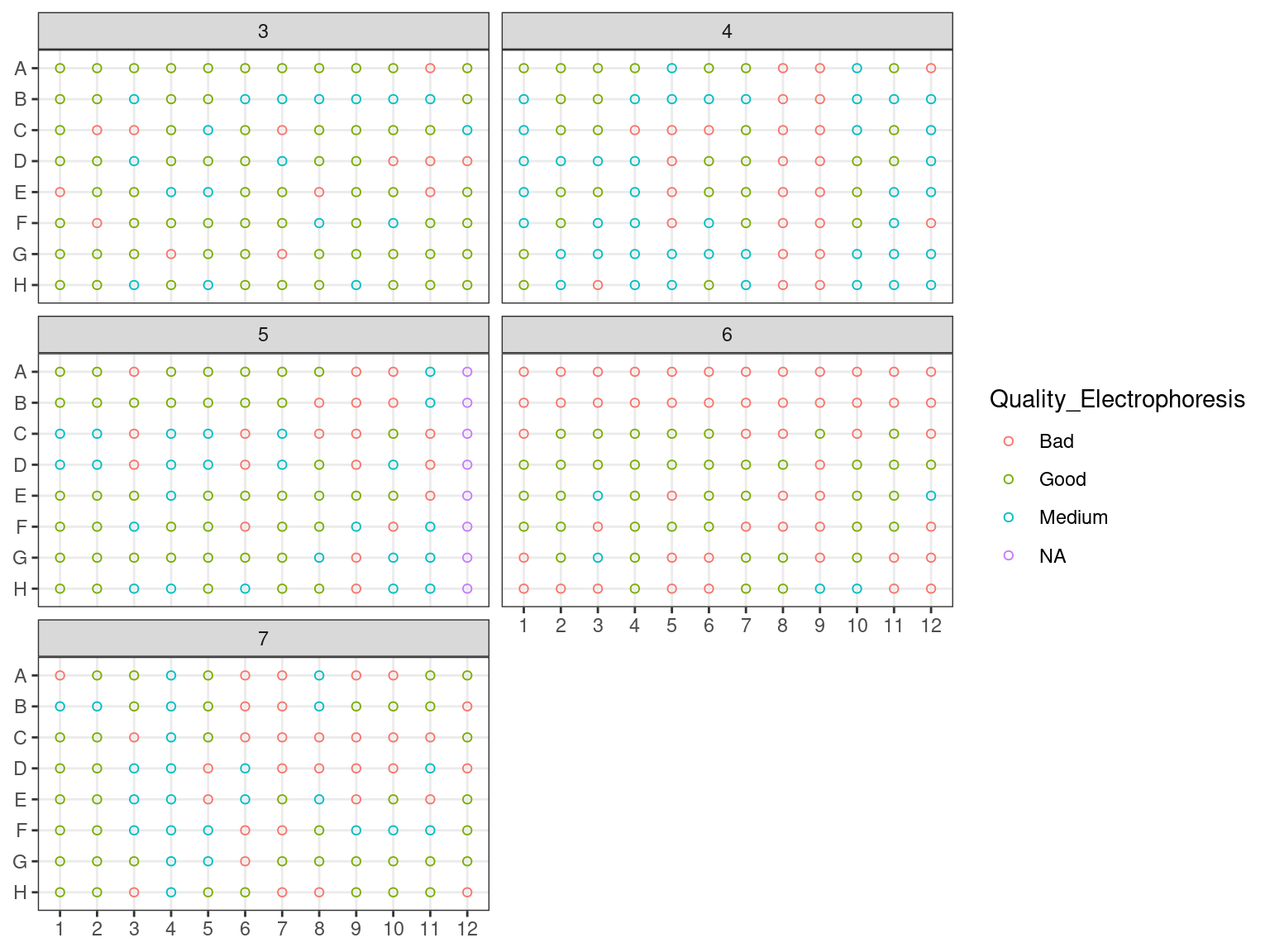
Figure 3.4: Extraction plate Electrophoresis quality
3.1.2 Library plates design
We first designed new plates based on the samples concentration in order to bring all samples to the same concentration for further easier manipulations in library preparation.
3.1.2.1 Pool
We pooled all individuals with 2 extractions and with a nanodrop concentration inferior to 25 \(ng.\mu L^{-1}\). Individuals with only one extraction were further concentrated. Warning, P7-3-2812 has been pooled from P2.C12 to P7.C12 instead of P7.D12.
| ID | Plate_extraction | Position_extraction | nanodrop |
|---|---|---|---|
| P10_3_2912 | 1 | G10 | NA |
| P10_3_2912 | 6 | G10 | 10.70 |
| P11_1_742 | 3 | C2 | 23.29 |
| P11_1_742 | 5 | D3 | 18.96 |
| P13_2_2819 | 2 | F5 | NA |
| P13_2_2819 | 7 | F5 | 21.52 |
3.1.2.2 Pool and new samples nanodrop
Pooled individuals and new individuals from Itubera Brazil (n = 3), La Selva Costa Rica (n = 2) and Barro Colorado Island Panama (n = 2) have been quantified again with the nanodrop.
| ID | nanodrop | Plate | Position |
|---|---|---|---|
| P4-2-3487 | 20.71 | Pull | NA |
| LS-SG18 | 49.53 | America | NA |
| IT_H5 | 12.86 | Itubera | H5 |
| IT_H3 | 16.37 | Itubera | H3 |
| IT_B4 | 19.42 | Itubera | B4 |
3.1.2.3 Concentration Plates
We reorganised plates in a new scheme ordered by concentration following figure 3.5 design with figure 3.6 concentrations.

Figure 3.5: Previous extraction position in plates arranged by concentration.
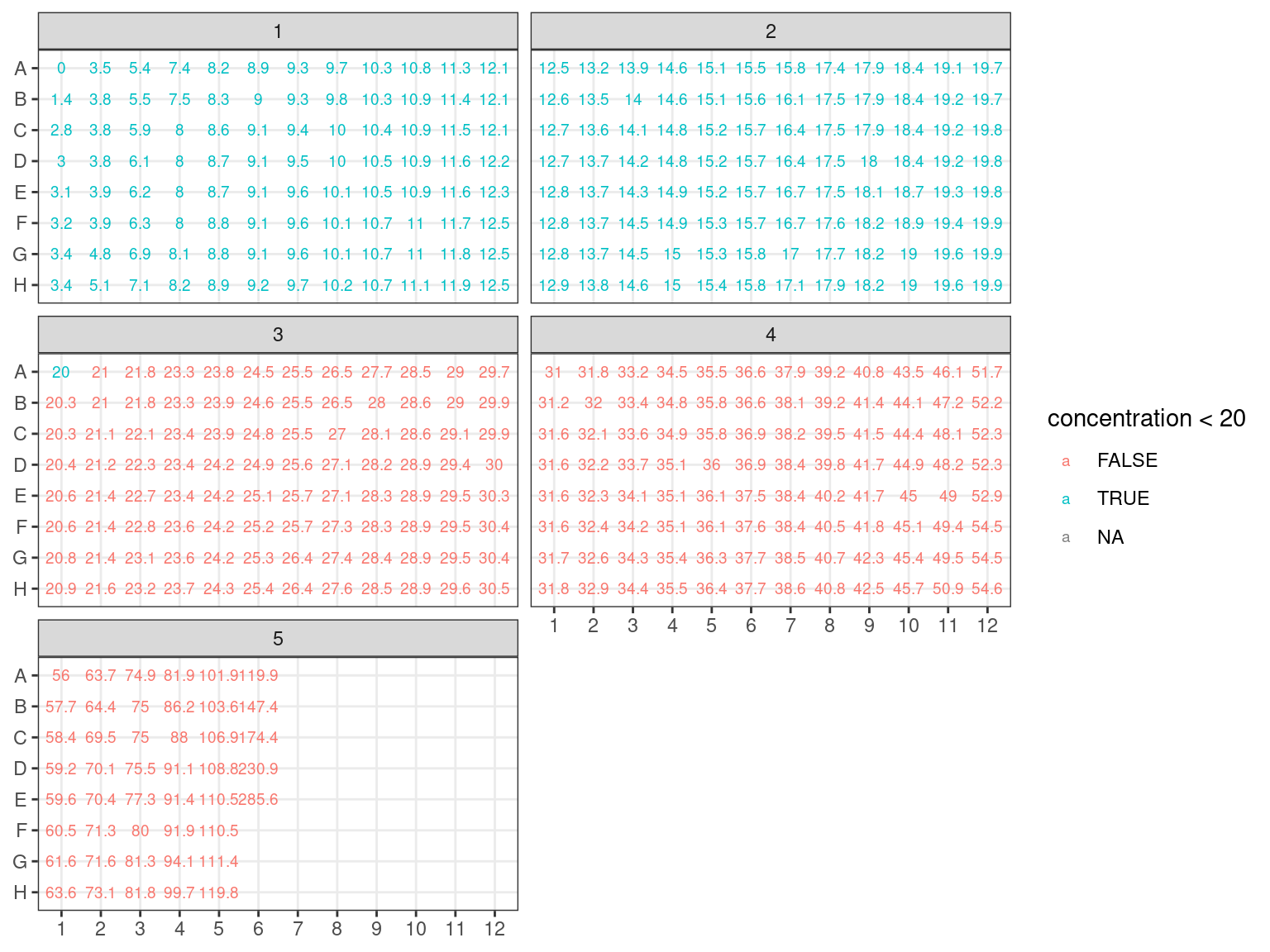
Figure 3.6: Concentration in plates arranged by concentration.
3.1.2.4 Samples volume
In order to adjust samples concentration we needed first to assess their current volume, see figure 3.7. Volume after extraction was around 45 \(\mu L\) (estimated loss). Samples have lost volume with NanoDrop, Qubit, electrophoresis, and libraries trial, one or two times. Some samples gained volume with pooling. We can consider all samples to have lost 1 \(\mu L\) with NanoDrop. Samples used in Qubit lost an additional 1.5 to 3 \(\mu L\). Finally samples used in trial libraries lost between 0.5 and 5 \(\mu L\) (with library test II repeated). Pooled samples from plate 5, 6 an 7 gained 49 \(\mu L\) from NanoDrop samples from plate 1, 2, 3 and 4 unused for NanoDrop, Qubit nor libraries trial (original 50 minus 1 due to NanoDrop measurement). Added samples from Itubera, La Selva and Barro Colorado Island have an estimated volume of 10 \(\mu L\) (overestimated).
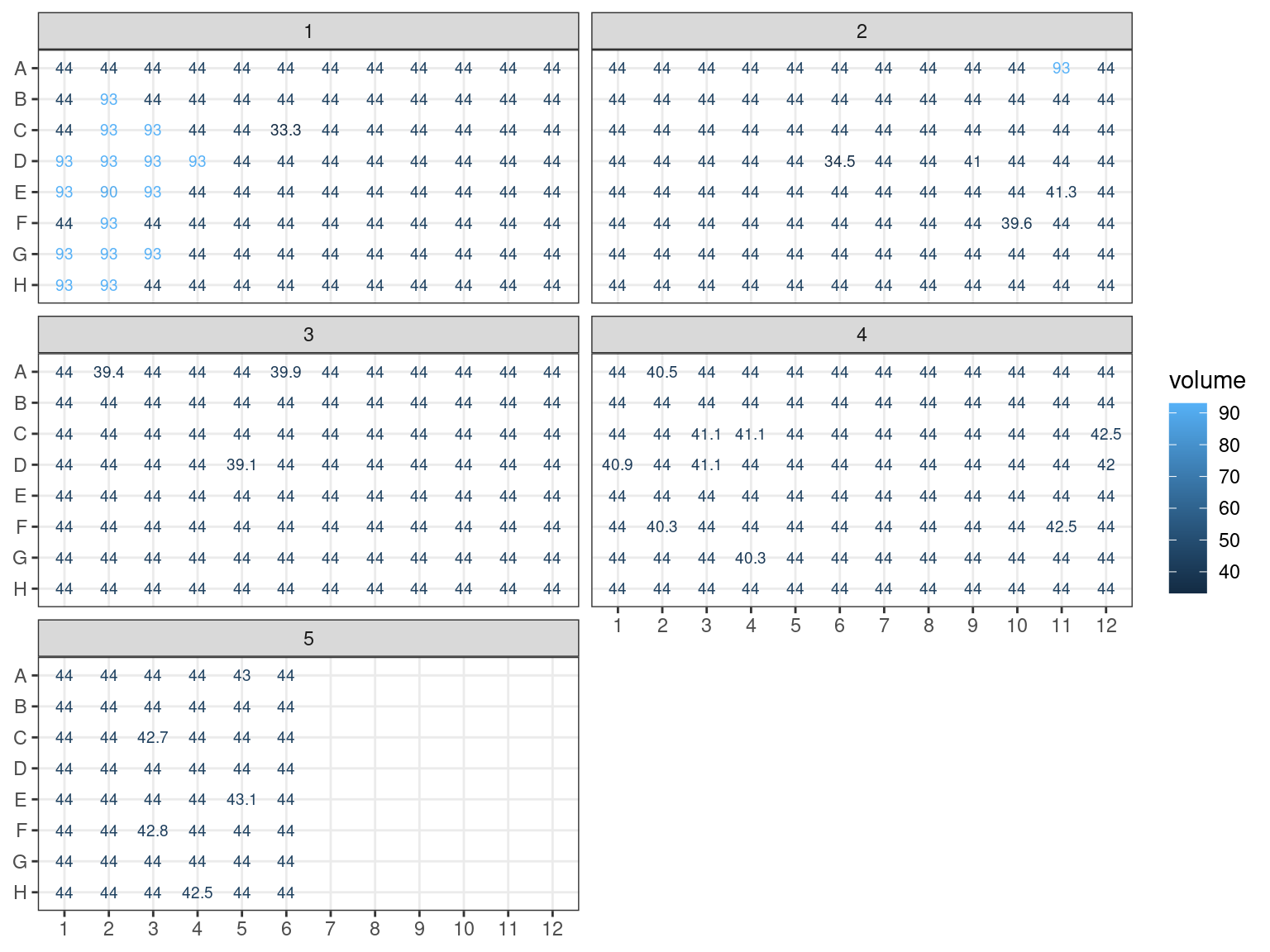
Figure 3.7: Samples estimated volumes.
3.1.2.5 DNA quality
We assessed DNA fragment quality and size through electrophoresis and reorganized columns inside plates by quality.
## # A tibble: 192 x 7
## # Groups: ID [192]
## ID source_Plate source_Position volumeplus5 concentration dest_Plate
## <chr> <chr> <chr> <dbl> <dbl> <chr>
## 1 MHDN… PCR1 B1 49 1.44 PCR2
## 2 P15_… PCR1 D1 50 3.00 PCR2
## 3 P3_2… PCR1 E1 50 3.10 PCR2
## 4 MHDN… PCR1 F1 49 3.17 PCR2
## 5 P5_4… PCR1 G1 50 3.36 PCR2
## 6 P13_… PCR1 H1 50 3.45 PCR2
## 7 P13_… PCR1 F2 50 3.93 PCR2
## 8 P7_3… PCR1 G2 50 4.76 PCR2
## 9 EE16… PCR1 A3 49 5.44 PCR2
## 10 MH31… PCR1 B3 49 5.47 PCR2
## # … with 182 more rows, and 1 more variable: dest_Position <chr>## # A tibble: 192 x 7
## # Groups: ID [192]
## ID source_Plate source_Position volumeplus5 concentration dest_Plate
## <chr> <chr> <chr> <dbl> <dbl> <chr>
## 1 P15_… PCR1 E3 49 22.7 PCR2
## 2 P1_4… PCR1 H3 49 23.2 PCR2
## 3 OH29… PCR1 D5 44.1 24.2 PCR2
## 4 P4_2… PCR1 F5 49 24.2 PCR2
## 5 P13_… PCR1 G5 49 24.2 PCR2
## 6 P7_2… PCR1 C6 49 24.8 PCR2
## 7 P4_1… PCR1 E6 49 25.1 PCR2
## 8 P16_… PCR1 A7 49 25.5 PCR2
## 9 P10_… PCR1 D7 49 25.6 PCR2
## 10 P10_… PCR1 F7 49 25.7 PCR2
## # … with 182 more rows, and 1 more variable: dest_Position <chr>## # A tibble: 48 x 7
## # Groups: ID [48]
## ID source_Plate source_Position volumeplus5 concentration dest_Plate
## <chr> <chr> <chr> <dbl> <dbl> <chr>
## 1 P3_2… PCR1 A1 49 56.0 PCR2
## 2 P7_2… PCR1 B1 49 57.7 PCR2
## 3 P13_… PCR1 F1 49 60.5 PCR2
## 4 P6_4… PCR1 H1 49 63.6 PCR2
## 5 P7_3… PCR1 A2 49 63.7 PCR2
## 6 P15_… PCR1 B2 49 64.4 PCR2
## 7 P7_3… PCR1 C2 49 69.5 PCR2
## 8 P13_… PCR1 D2 49 70.1 PCR2
## 9 P7_3… PCR1 H2 49 73.1 PCR2
## 10 P15_… PCR1 C3 47.7 75.0 PCR2
## # … with 38 more rows, and 1 more variable: dest_Position <chr>| ID | Plate_concentration | Position_concentration | volumeplus5 | concentration | Plate_library | Position_library |
|---|---|---|---|---|---|---|
| P15_3_267 | 1 | D1 | 98 | 3.002452 | 1 | B1 |
| P3_2_739 | 1 | E1 | 98 | 3.096646 | 1 | C1 |
| P5_4_658 | 1 | G1 | 98 | 3.355682 | 1 | E1 |
| P13_2_929 | 1 | H1 | 98 | 3.446932 | 1 | F1 |
| P13_4_149 | 1 | F2 | 98 | 3.929680 | 1 | G1 |
| P7_3_2837 | 1 | G2 | 98 | 4.762713 | 1 | H1 |
| P4_1_3000 | 1 | C3 | 98 | 5.895991 | 1 | C2 |
| P6_3_346 | 1 | E3 | 98 | 6.172688 | 1 | D2 |
| P11_1_742 | 1 | G3 | 98 | 6.908583 | 1 | E2 |
| P7_3_679 | 1 | B2 | 98 | 3.761896 | 1 | B4 |
| P15_4_40 | 1 | C2 | 98 | 3.829598 | 1 | C4 |
| P7_2_3049 | 1 | D2 | 98 | 3.847259 | 1 | F7 |
| P10_3_2912 | 1 | E2 | 95 | 3.912018 | 1 | G7 |
| P7_2_2520 | 1 | H2 | 98 | 5.086507 | 1 | H7 |
| P4_2_3487 | 1 | D3 | 98 | 6.096155 | 1 | A8 |
| P6_3_2800 | 1 | D4 | 98 | 7.997708 | 1 | D8 |
| P7_3_2812 | 2 | A11 | 98 | 19.118554 | 2 | F3 |
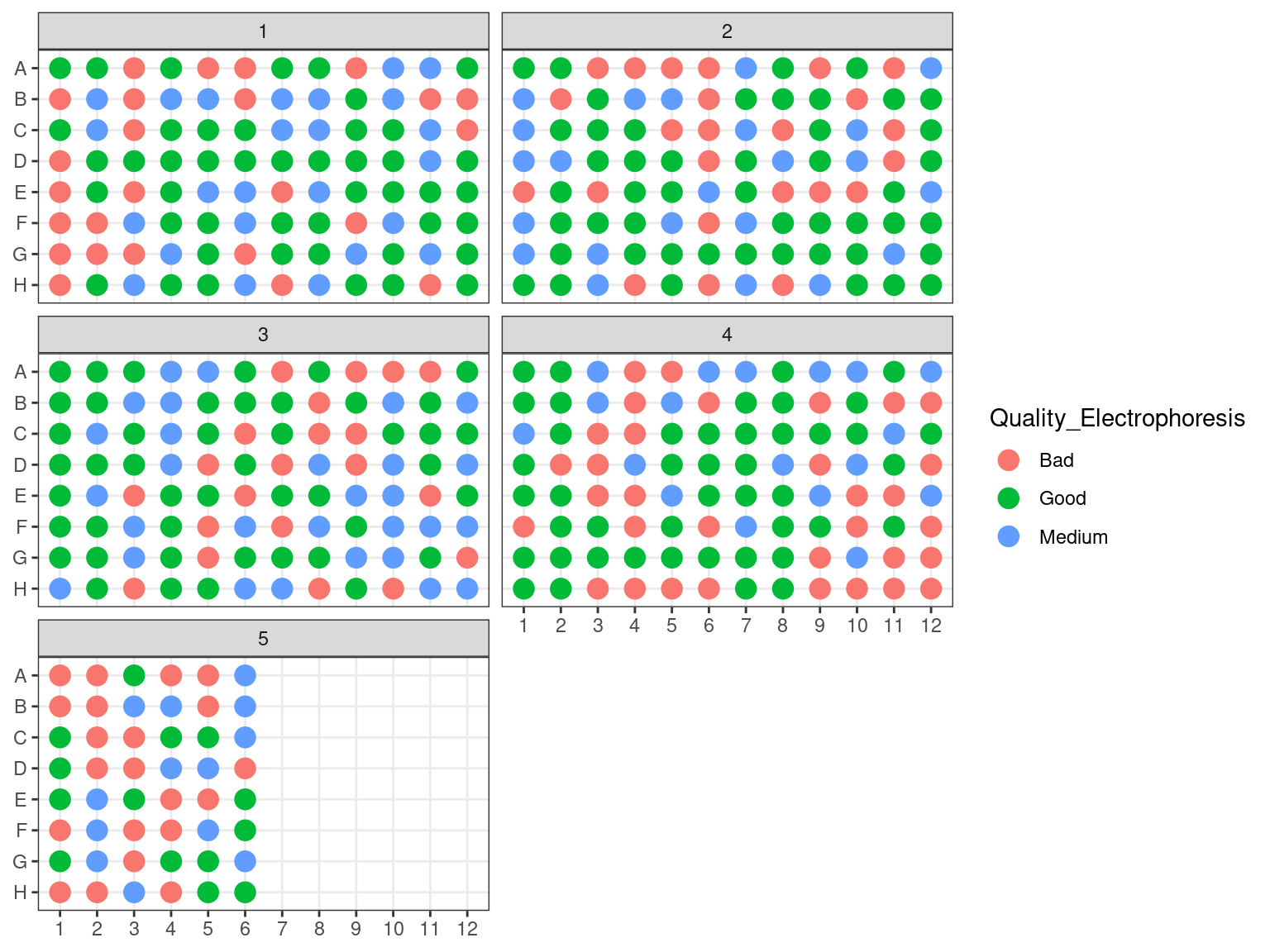
Figure 3.8: Plates electrophoresis status before rearrangement.
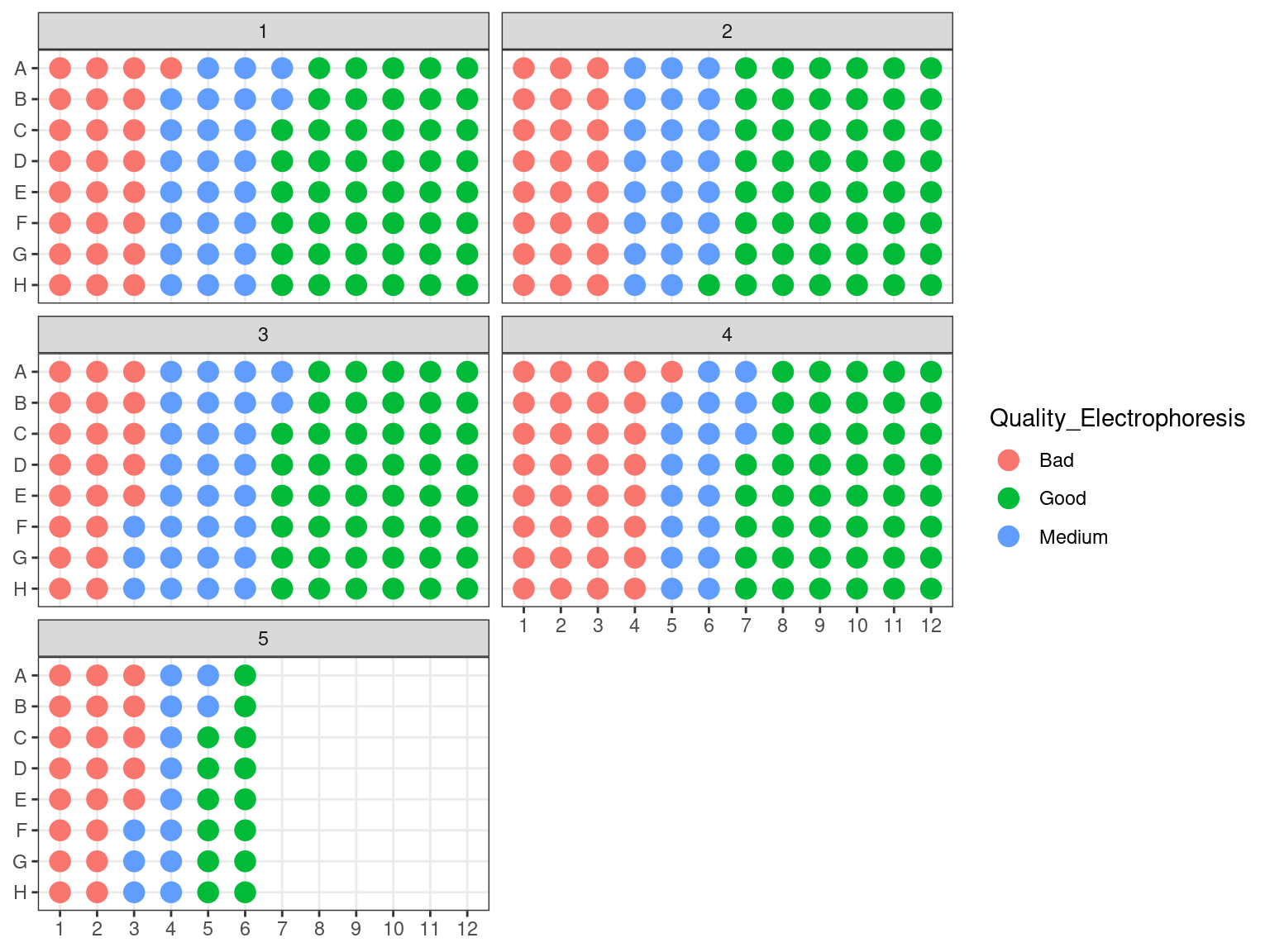
Figure 3.9: Plates electrophoresis status after rearrangement.
3.1.2.6 Concentration
All individuals with an estimated concentration inferior to 19 \(ng.\mu L^{-1}\) (Plates 1 and 2) have been dried in the speed vacuum centrifuge. And corresponding volume of milliQ water will be added to reach a concentration of 20 \(ng.\mu L^{-1}\) (or at least 6.5 \(\mu L\) to reach sample volume). Their DNA content in \(ng\) has been computed multiplying concentration with volume. The volume of water to add is thus the DNA content divided by the objective concentration of 20 \(ng.\mu L^{-1}\): \(V = \frac{C_0*V_0}{20}\). Corresponding volumes are shown in figure 3.11.
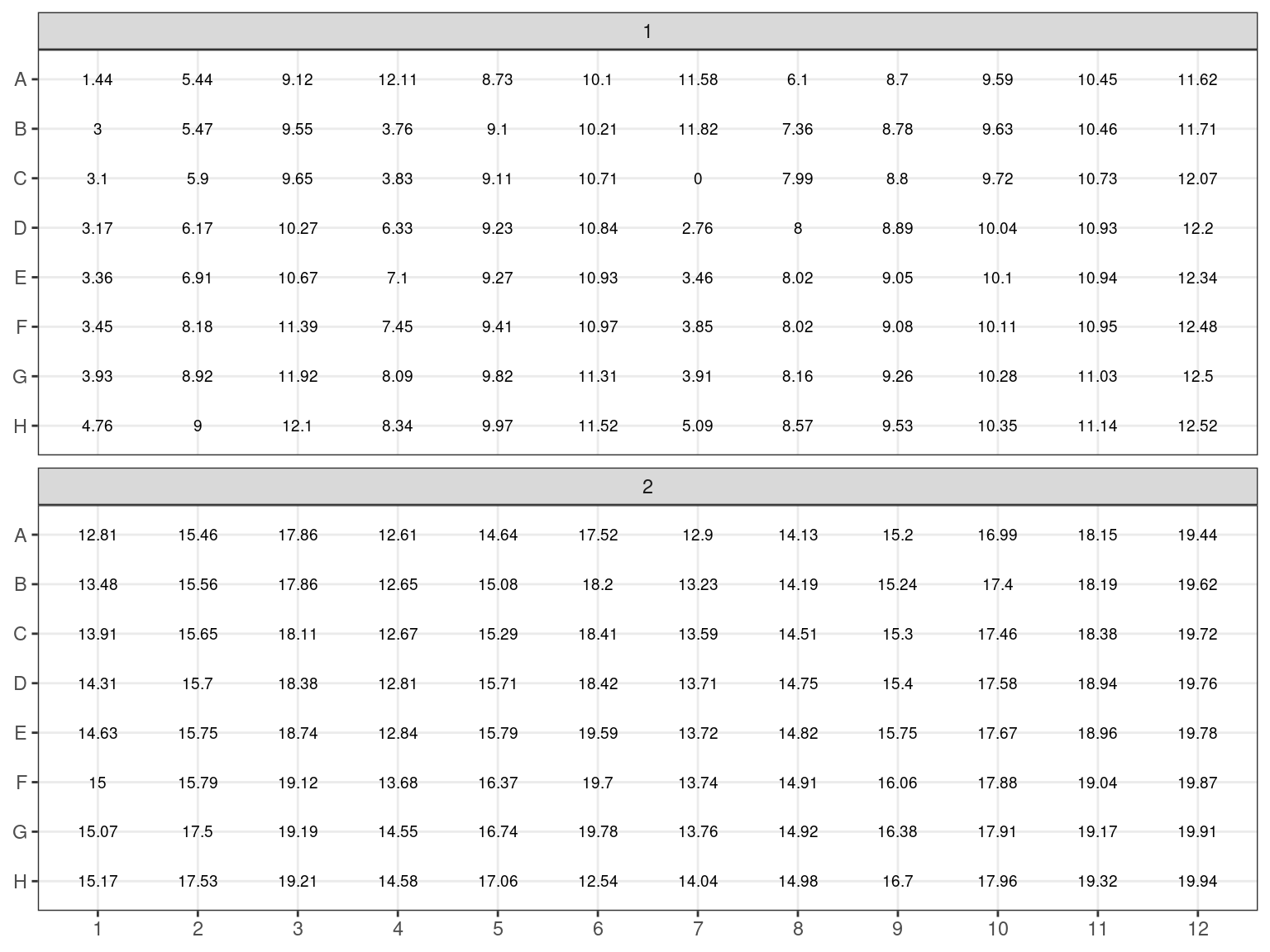
Figure 3.10: Samples to be concentrated. Estimated concentration in ng/microL
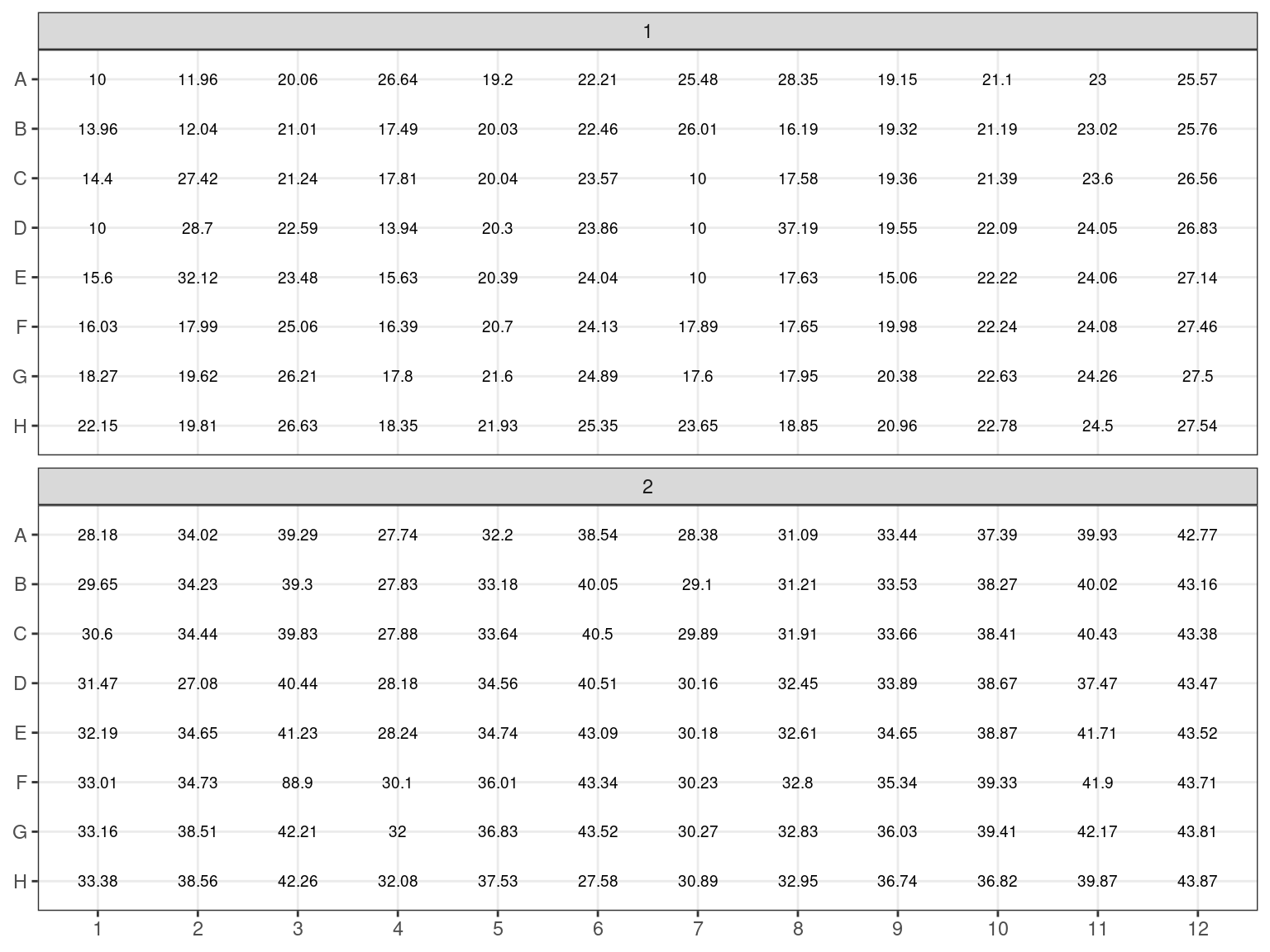
Figure 3.11: Volume to resuspend dry samples.
## # A tibble: 192 x 6
## source_Plate source_Position sample_volume new_volume dest_Plate
## <chr> <chr> <dbl> <dbl> <chr>
## 1 PCR1 A1 0 10 PCR2
## 2 PCR1 B1 0 14 PCR2
## 3 PCR1 C1 0 14.4 PCR2
## 4 PCR1 D1 0 10 PCR2
## 5 PCR1 E1 0 15.6 PCR2
## 6 PCR1 F1 0 16 PCR2
## 7 PCR1 G1 0 18.3 PCR2
## 8 PCR1 H1 0 22.1 PCR2
## 9 PCR1 A2 0 12 PCR2
## 10 PCR1 B2 0 12 PCR2
## # … with 182 more rows, and 1 more variable: dest_Position <chr>3.1.2.7 Samples volume
The objective was to get 100 \(ng\) of DNA in 6.5 \(\mu L\) of sample for the library preparation. Consequently we needed to extract with the robot \(V = \frac{n}{C} = \frac{100}{C}\) with \(C\) the sample concentration in \(ng.\mu L^{-1}\).
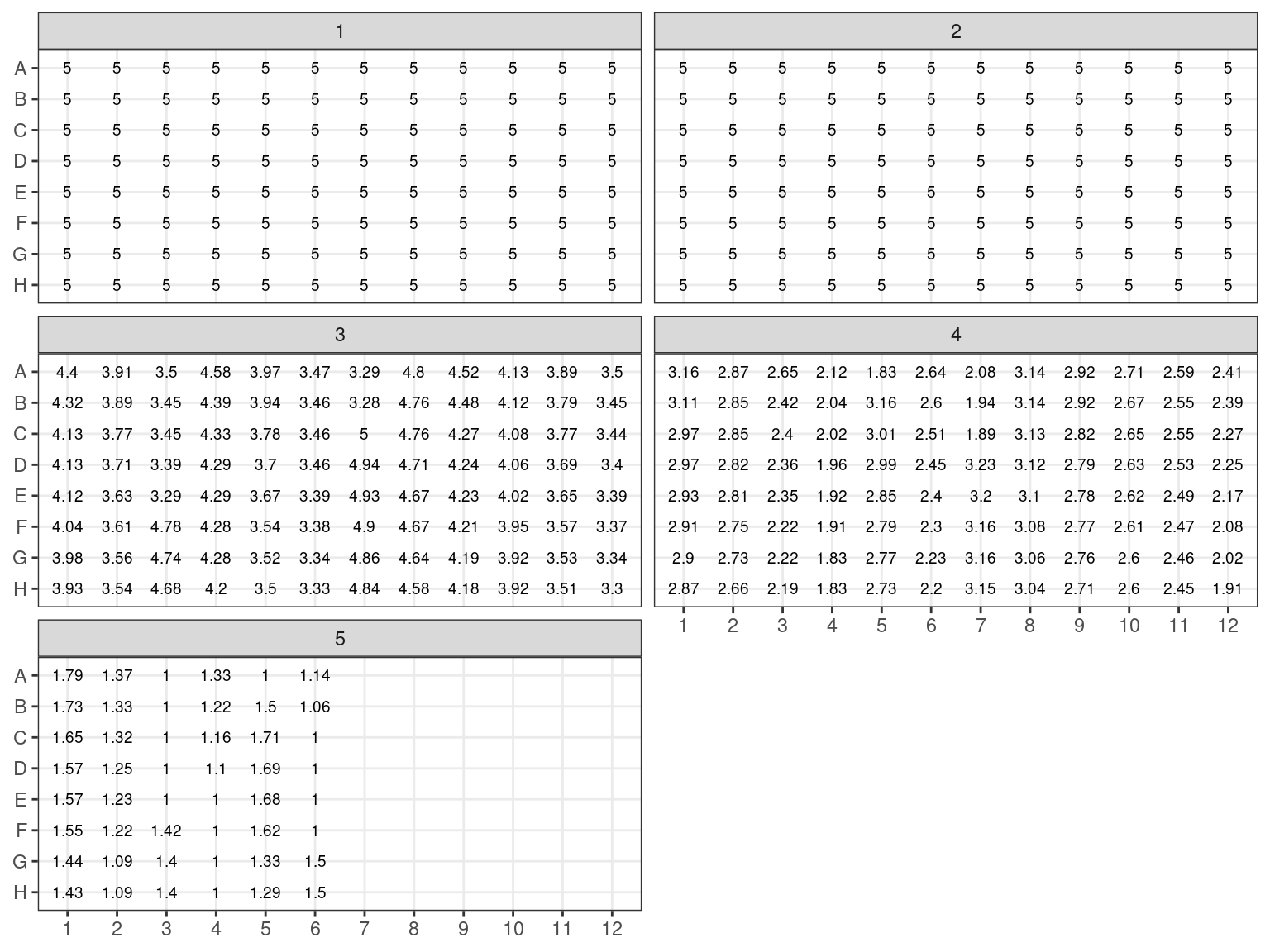
Figure 3.12: Sample volume (microL)
## # A tibble: 192 x 7
## # Groups: ID [192]
## ID source_Plate source_Position sample_volume water_volume dest_Plate
## <chr> <chr> <chr> <dbl> <dbl> <chr>
## 1 P15_… PCR1 A1 4.4 2.1 PCR2
## 2 P1_4… PCR1 B1 4.3 2.2 PCR2
## 3 OH29… PCR1 C1 4.1 2.4 PCR2
## 4 P4_2… PCR1 D1 4.1 2.4 PCR2
## 5 P13_… PCR1 E1 4.1 2.4 PCR2
## 6 P7_2… PCR1 F1 4 2.5 PCR2
## 7 P4_1… PCR1 G1 4 2.5 PCR2
## 8 P16_… PCR1 H1 3.9 2.6 PCR2
## 9 P10_… PCR1 A2 3.9 2.6 PCR2
## 10 P10_… PCR1 B2 3.9 2.6 PCR2
## # … with 182 more rows, and 1 more variable: dest_Position <chr>## # A tibble: 48 x 7
## # Groups: ID [48]
## ID source_Plate source_Position sample_volume water_volume dest_Plate
## <chr> <chr> <chr> <dbl> <dbl> <chr>
## 1 P3_2… PCR1 A1 3.6 9.4 PCR2
## 2 P7_2… PCR1 B1 3.5 9.5 PCR2
## 3 P13_… PCR1 C1 3.3 9.7 PCR2
## 4 P6_4… PCR1 D1 3.1 9.9 PCR2
## 5 P7_3… PCR1 E1 3.1 9.9 PCR2
## 6 P15_… PCR1 F1 3.1 9.9 PCR2
## 7 P7_3… PCR1 G1 2.9 10.1 PCR2
## 8 P13_… PCR1 H1 2.9 10.1 PCR2
## 9 P7_3… PCR1 A2 2.7 10.3 PCR2
## 10 P15_… PCR1 B2 2.7 10.3 PCR2
## # … with 38 more rows, and 1 more variable: dest_Position <chr>| Plate_library | Position_library | sample_volume | water_volume |
|---|---|---|---|
| 3 | F3 | 4.782128 | 1.717872 |
| 3 | G3 | 4.742738 | 1.757262 |
| 3 | H3 | 4.676794 | 1.823206 |
| 3 | A4 | 4.579085 | 1.920915 |
| 3 | C7 | 5.004011 | 1.495988 |
| 3 | D7 | 4.935673 | 1.564327 |
| 3 | E7 | 4.933522 | 1.566478 |
| 3 | F7 | 4.896546 | 1.603454 |
| 3 | G7 | 4.860815 | 1.639185 |
| 3 | H7 | 4.843489 | 1.656511 |
| 3 | A8 | 4.799016 | 1.700984 |
| 3 | B8 | 4.764021 | 1.735979 |
| 3 | C8 | 4.757350 | 1.742650 |
| 3 | D8 | 4.708556 | 1.791444 |
| 3 | E8 | 4.669723 | 1.830277 |
| 3 | F8 | 4.665875 | 1.834125 |
| 3 | G8 | 4.639748 | 1.860252 |
| 3 | H8 | 4.582792 | 1.917208 |
| 3 | A9 | 4.520590 | 1.979410 |
3.2 Libraries preparation protocol
The protocol is given per sample with the corresponding volume for a plate of 96 samples in bracket.
3.2.1 Material preparation
- 0.5 \(\mu L\) of 10mM TrisHCL + 10 mM NaCl (48 \(\mu L\) per plate)
- 46.875 \(\mu L\) of 0.1X TE buffer (2 136.875 \(\mu L\) per plate) = 4.7 \(\mu L\) of TE buffer (213.7 \(\mu L\) per plate) + 42.3 \(\mu L\) of water (1 923.3 \(\mu L\) per plate)
- 400 \(\mu L\) of fresh 80% Ethanol (38 400 \(\mu L\) per plate)
3.2.2 Fragmentation
- Prepare 6.5 \(\mu L\) of samples with ca 100 \(ng\) of DNA (see previous chapter)
- On ice, pipette up and down ULTRA II FS Reaction Buffer 10X, vortex 5" and spin
- On ice, vortex 5" Ultra II FS Enzyme Mix and spin
- On ice, premix 0.5 \(\mu L\) of Ultra II FS Enzyme Mix (48 \(\mu L\) per plate) with 1.75 \(\mu L\) of Ultra II FS Reaction Buffer (168 \(\mu L\) per plate), vortex and spin
- On ice, add 2.25 \(\mu L\) of premix to each sample, vortex 5" and spin:
| Component | Volume per library | Volume per plate |
|---|---|---|
| DNA | 6.5 \(\mu L\) | |
| Ultra II FS Enzyme Mix | 0.5 \(\mu L\) | 48 \(\mu L\) |
| Ultra II FS Reaction Buffer | 1.75 \(\mu L\) | 168 \(\mu L\) |
| Total | 8.75 \(\mu L\) |
- Thermocycle with following programs depending on electrophoresis quality:
- Optionally, put the NEBNext adaptor for Illumina out of the freezer (long to melt)
- Optionally, samples can be stored overnight at \(-20^\circ\)
3.2.3 Adaptor ligation
- On ice, prepare diluted adaptor (1:5) with 0.125 \(\mu L\) of NEBNext adaptor for Illumina (12 \(\mu L\) per plate) diluted into 0.5 \(\mu L\) of 10mM TrisHCL + 10 mM NaCl (48 \(\mu L\) per plate)
- On ice, premix 7.5 \(\mu L\) of NEBNext Ultra II Ligation Master Mix (720 \(\mu L\) per plate) with 0.25 \(\mu L\) of NEBNext ligation enhancer (24 \(\mu L\) per plate), vortex and spin
- On ice, add 0.625 \(\mu L\) of diluted adaptor and 7.75 \(\mu L\) of premix to samples, mix and spin:
| Component | Volume per library | Volume per plate |
|---|---|---|
| DNA | 8.75 \(\mu L\) | |
| NEBNext Ultra II Ligation Master Mix | 7.5 \(\mu L\) | 720 \(\mu L\) |
| NEBNext ligation enhancer | 0.25 \(\mu L\) | 24 \(\mu L\) |
| diluted NEBNext adaptor (1:5) | 0.625 \(\mu L\) | 50 \(\mu L\) |
| Total | 17.25 \(\mu L\) |
3.2.4 Size selection
- Bring the sample volume from 17.125 \(\mu L\) to 27.125 \(\mu L\) adding 10 \(\mu L\) of 0.1X TE buffer (1 716 \(\mu L\) per plate)
- Vortex PGTB beads from batch E at room temperature
- Add 7 \(\mu L\) (~0.28X) of beads (672 \(\mu L\) per plate) to each sample, mix, vortex 5" keeping beads, incubet 5’, spin, place on magnet, wait 5’, and transfer ~32 \(\mu L\) of sample to a new plate
- Add 3.5 \(\mu L\) (~0.14X) of beads (336 \(\mu L\) per plate) to each sample, mix, wait 5’ without the magnet
- Place on magnet, wait 5" and discard ~35.5 \(\mu L\) of supernatant
- Add 100 \(\mu L\) of fresh 80% Ethanol (9 600 \(\mu L\) per plate) to the beads on the magnet, wait 30’ remove supernatant
- Repeat, add 100 \(\mu L\) of fresh 80% Ethanol (9 600 \(\mu L\) per plate) to the beads on the magnet, wait 30" remove supernatant
- Air dry beads 3’ on magnet
- Remove magnet, elute into 12 \(\mu L\) of hot 0.1X TE (1 152 \(\mu L\) per plate) (~40°C), mix, incubate 2’, spin, put on magnet, wait 5’
- Transfer 2 x 5 \(\mu L\) of supernatant to 2 new plates
- Optionally, samples can be stored overnight at \(-20^\circ\)
3.2.5 Enrichment and purification
protocol given for delivered oligos at \(100mM\), not NEBNext tag at \(10mM\)
- Prepare diluted index (1:10) with 0.16 \(\mu L\) of Index Primer i5 and i7 diluted in 1.44 \(\mu L\) of mQ \(H_2O\) (1.92 \(\mu L\) of i5 per row and 1.28 \(\mu L\) of i7 per column)
- Mix in each plate (2 for the 2 PCR), mix and spin :
| Component | Volume per library | Volume per plate/row/column |
|---|---|---|
| sample | 5 \(\mu L\) | |
| NEBNext Ultra II Q5 Master Mix | 8.3 \(\mu L\) | 796.8 \(\mu L\) |
| diluted Index Primer i5 (1:10) | 1.6 \(\mu L\) | 19.2 \(\mu L\) |
| diluted Index Primer i7 (1:10) | 1.6 \(\mu L\) | 12.8 \(\mu L\) |
| Total | 16.5 \(\mu L\) |
- Thermocycle with following program
- Optionally, amplify only the first plate, assess it with electrophoresis, and adjust cycles number for the second amplification depending on gel migration
- Pool PCR results (~16.5 \(\mu L\) per sample) from the 2 plates into one (~33.3K \(\mu L\) per sample)
- Vortex PGTB beads from batch E at room temperature
- Add 30 \(\mu L\) (~0.9X) of beads (2 880 \(\mu L\) per plate), mix, vortex 5" keeping beads, spin, place on magnet, wait 5’, and remove supernatant (~ 63 \(\mu L\) per sample)
- Add 100 \(\mu L\) of fresh 80% Ethanol (9 600 \(\mu L\) per plate), wait 30’ remove supernatant
- Repeat, add 100 \(\mu L\) of fresh 80% Ethanol (9 600 \(\mu L\) per plate), wait 30" remove supernatant
- Air dry beads 3’ on magnet
- Remove magnet, elute into 22 \(\mu L\) of hot 0.1X TE (2 112 \(\mu L\) per plate) (~40°C), mix, incubate 2’, and spin
- Place on magnet, wait 5’, transfer 22 \(\mu L\) of supernatant to a new plate and store at \(-20^\circ\)
3.3 Library preparation results
3.3.1 Post-enrichment PCR1 quantification
After the enrichment and the purification of the first PCR (PCR1), we quantified double strand DNA in every plate in order to adjust the second PCR (PCR2), and more specifically in order to increase the number of cycles in PCR2. We used both Quant-It and a few samples on Qubit and transformed raw absorbance results into concentration with regressions.

3.3.2 Post-enrichment (PCR1 & PCR2) and amplification quantification
Libraries showing no band or light smear in the electrophoresis have been amplified, resulting in amplified plates A1 and A2. We used the Quant-It to dose all samples (original libraries and amplified libraries).

3.3.3 Amplification result
We used electrophoresis and noticed if re-amplified samples had a band (B), a light smear (L) or nothing (A). Samples without anything (A) had their library repeated.

Figure 3.13: Electrophoresis Amplified
3.3.4 Library & extraction repetition result
69 libraries were still not satisfying after amplification. Those libraries have been rebuilt from source DNA. Among them, 43 were still not good at the electrophoresis and DNA has been re-extracted. Electrophoresis of re-extracted samples show a high heterogeneity of size, and around 8 of them seem to have not worked. All new samples have been quantified and libraries re-prepared according to the previously detailed protocol.
3.4 Capture
We did 16 reactions of gene capture by hybridization. Each reaction had up to 32 samples. We proceeded as follows:
- Amplifcation 1 Plate reorganization: plates state and volume have been assessed and 6 new plates (P1 to P6) have been built from (i) original libraries (P1-P5), (ii) reamplified libraries (A1-A2), and (iii) extraction and library repeat (P6). In order to do so, P6 stayed unchanged, and new plates 1 to 5 were either reamplified libraries or original libraries if not reamplified. Tip: remove unwanted cone from boxes when transferring original P1 to P5 to new ones to work with multi-channel pipette and prepare correspondence table to transfer reamplified plates A1 and A2 to new P1 to P5 plates crossing each line one-by-one.
- DNA dosage 1: with PicoGreen, we will assess DNA concentration of each sample with a ladder from 5 to 30 \(ng.\mu L^{-1}\) in order to correctly dose low concentration samples.
- Amplification 2: Samples that have never been reamplified with a concentration below 1 \(ng.\mu L^{-1}\) have been reorganized on a new plate (A3) and reamplified with 8 cycles.
- DNA dosage 2: Re-amplified samples (A3) have been dosed through NanoDrop and other more accurate technology depending on the availability.
- Amplifcation 2 and Library Repeat Plates reorganization: Re-amplified samples (A3) have been redistributed in their original position within library plates, and plates and 6.2 reorganized in a unique plate 6.3 for pools building.
- Pool building: Pool building followed plate organization, with re-extracted samples (P6.2) pooled together due to high fragment size heterogeneity. Pool building must be equimolar and thus depended on DNA dosage. Because we won’t pipette less than 0.5 \(\mu L\) of the most concentrated sample of one pool, depending on the concentration of the less concentrated sample, we needed to do dilution.
- Purification & Concentration: AMPure beads have been used to clean pools. We also used this step to concentrate samples in a smaller volume for the reaction (targeted volume of reaction is 7 \(\mu L\) with 100 to 500 \(ng\) of DNA).
- Size assessment: Pools fragments size have been assessed with TapeStation, in order to check for correct fragment size distribution, and, if needed, further clean library pools.
- Size selection: if size distribution result was not good enough, we further cleaned library pools through size selection with a Pippin. Info: we thus avoid failure of capture with too small fragments but we risk losing libraries.
- Capture: Finally we realized capture by hybridization following ArborScience protocol
3.4.1 Amplifcation 1 Plate reorganization
First amplification plates (A1 and A2) have been redistributed within their original library plates, removing previous libraries.
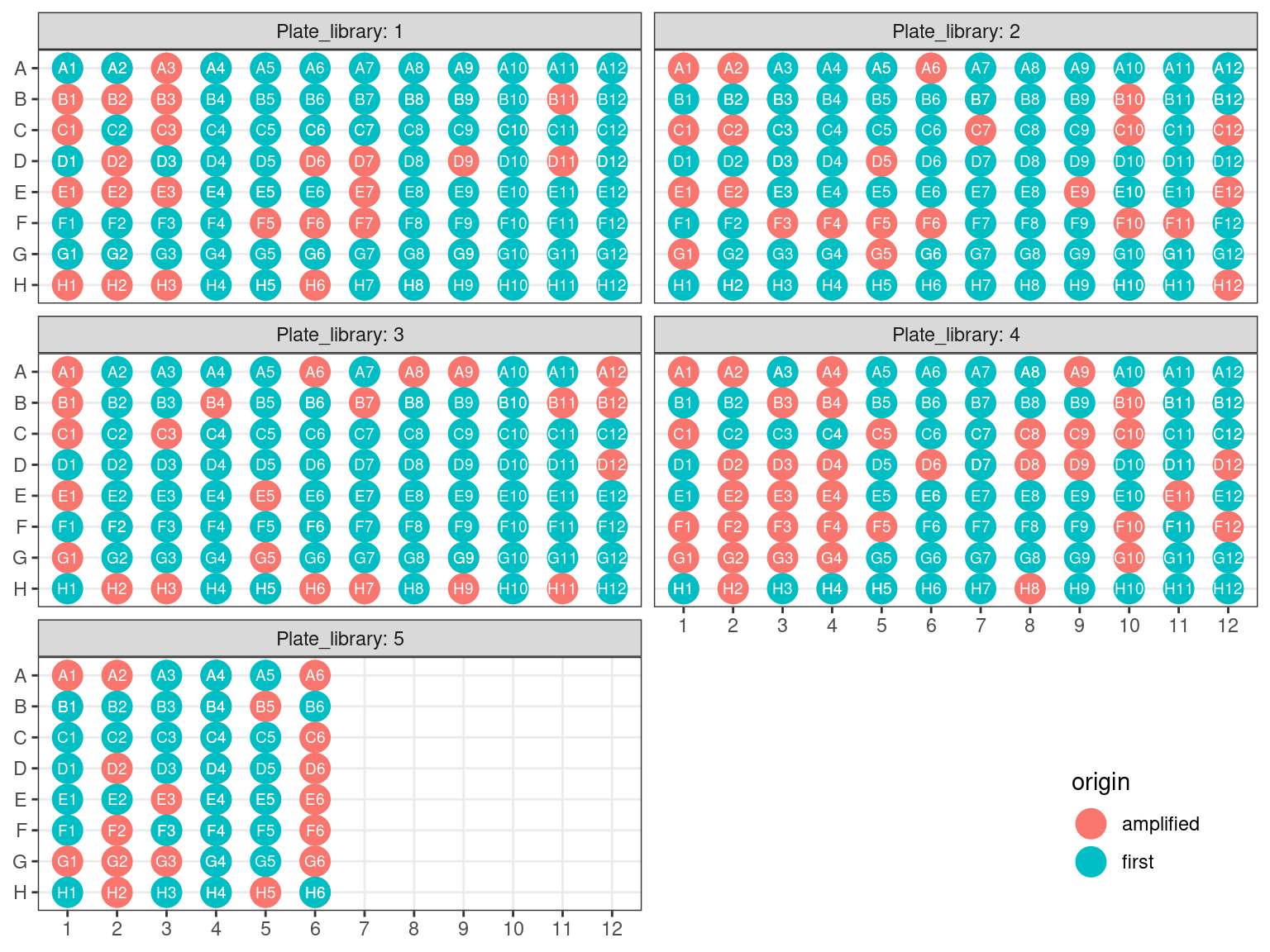
Figure 3.14: Original libraries to be kept (P1-P5).

Figure 3.15: Original position of amplified samples.
3.4.2 DNA dosage 1
Samples concentration has been assessed by PicoGreen with ca 60 samples having a concentration below \(1 ng.\mu L^{-1}\) among which 50 have not been reamplified (34 among original libraries, and the rest among repeated libraries or extractions). Those samples have been reamplified.
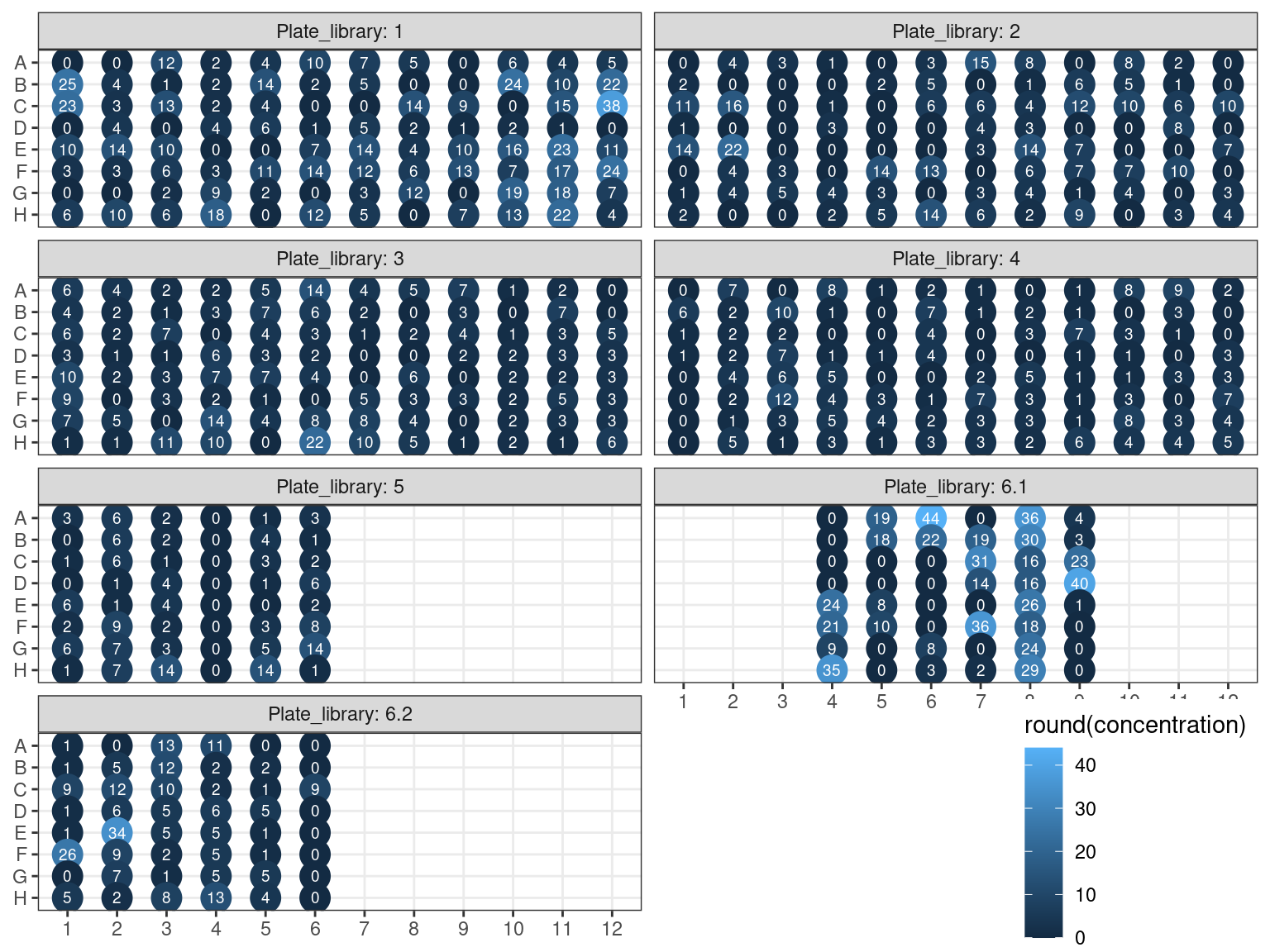
Figure 3.16: Sampled dosage by PicoGreen (concentration in ng.uL).
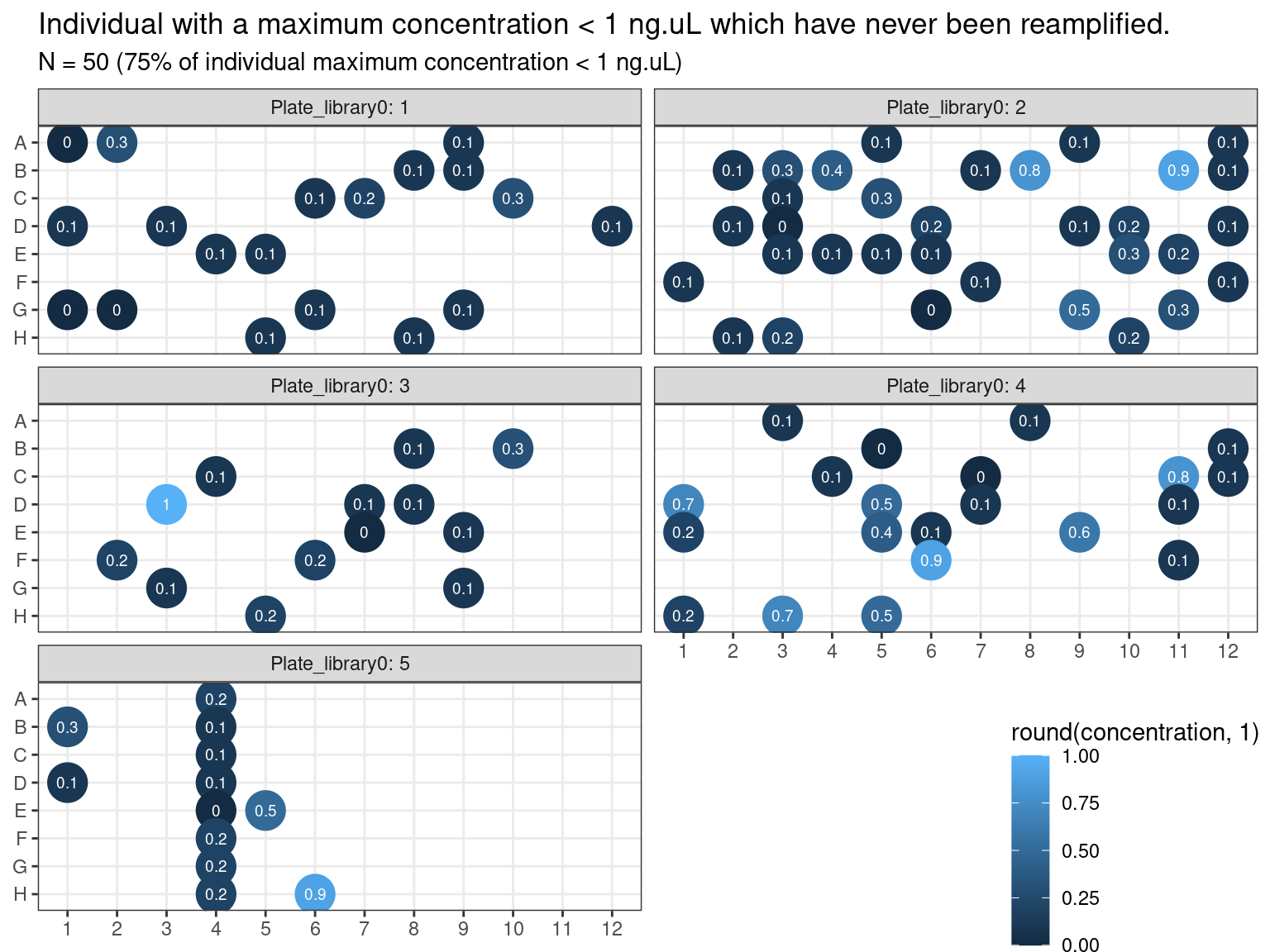
Figure 3.17: Samples to be re-amplified.
3.4.3 Amplification 2
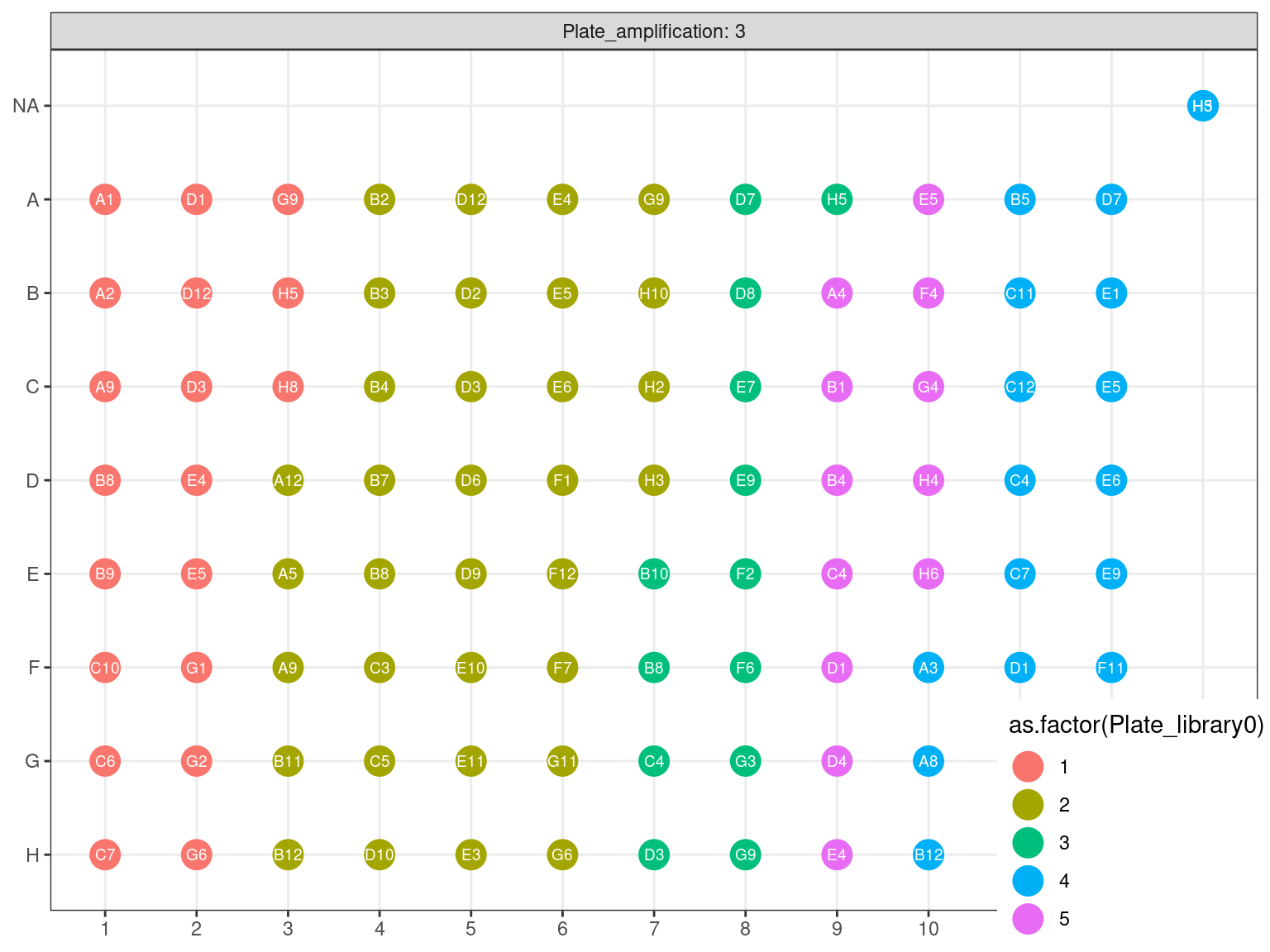
Figure 3.18: Original position of amplified samples in A3.
3.4.4 DNA dosage 2
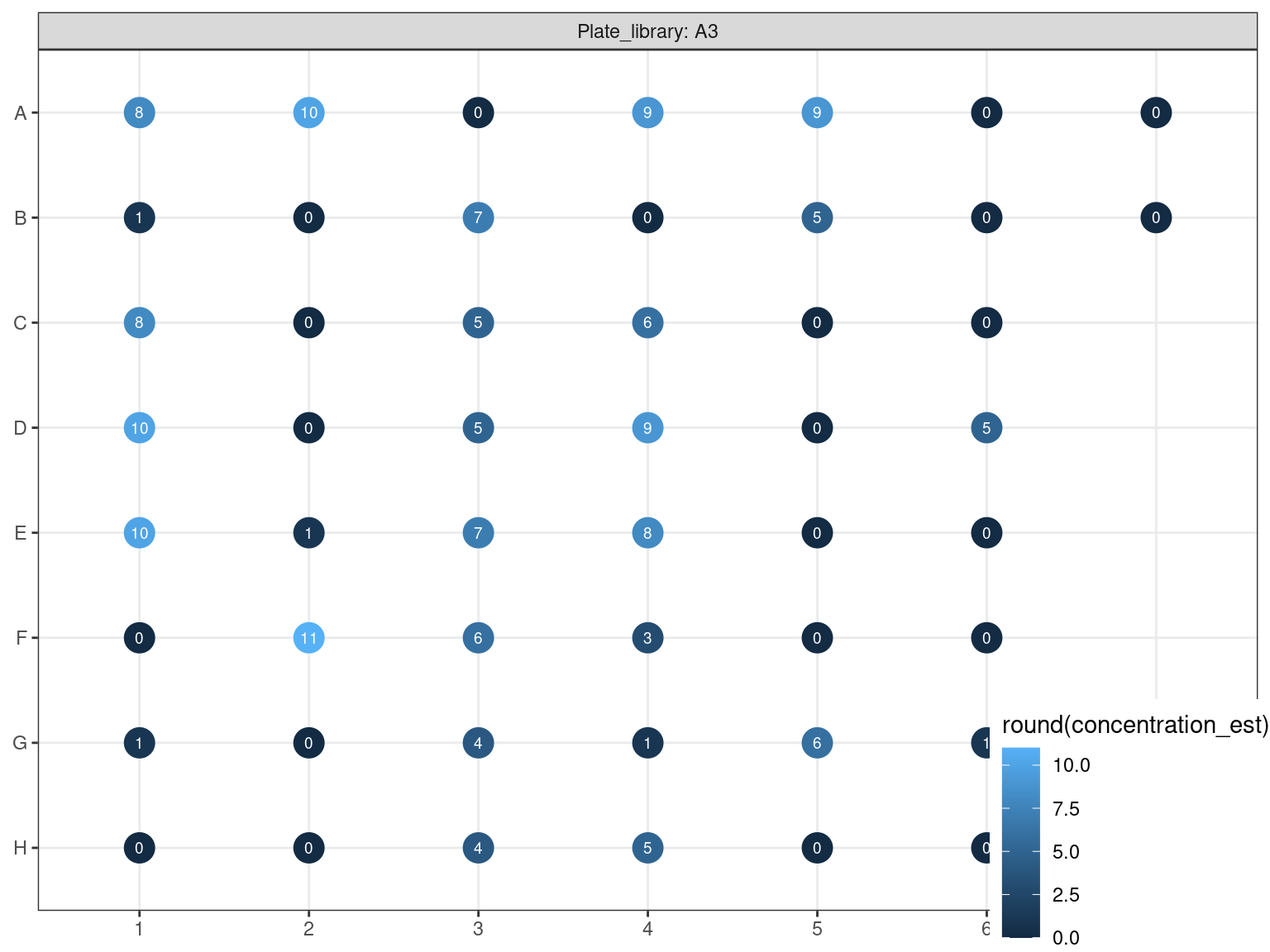
Figure 3.19: Reamplified samples dosed using PicoGreen (concentration in ng.uL).
3.4.5 Amplification 2 and Library Repeat Plates reorganization
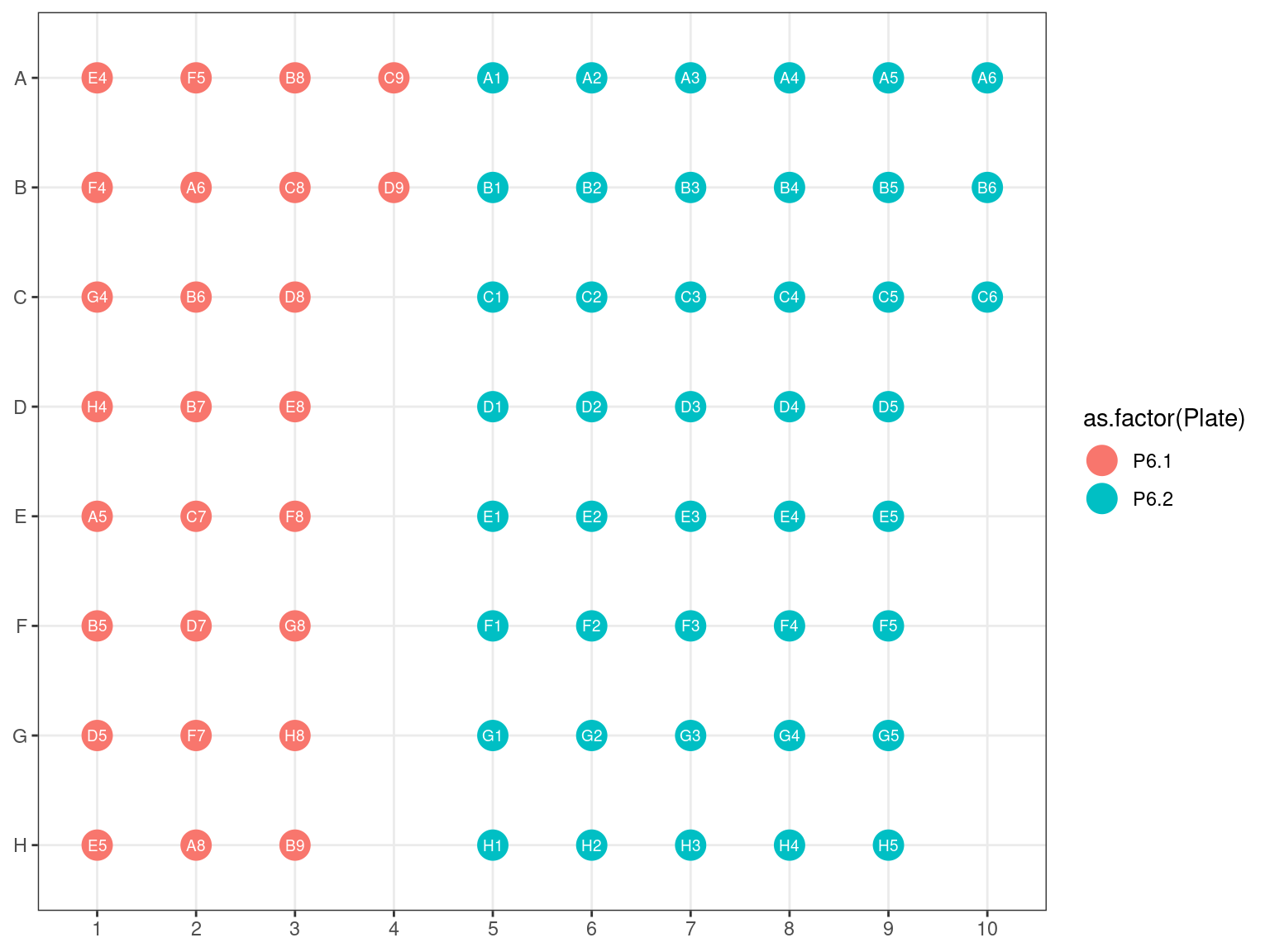
Figure 3.20: Original position of plates 6.1 and 6.2 reorganized plate 6.3.
3.4.6 Pool building
Due to non-uniformity of fragment size, re-extracted samples from P6 (P6.2) have been pooled into a single separated pool for the capture reaction (in total, we do 16 capture reactions on pooled samples, therefore we still have to constitute the 15 remaining pools). All other samples have been pooled by batches of 32 using the plate order illustrated in FIgure 3.21. We wanted 100 to 500 ng of DNA per reaction, and the reaction with the lowest number of samples had 16 samples. Consequently we used 15 ng of each sample, resulting in 240 to 645 ng of DNA per pool (but we may lose material in purification, so we aimed for extra). Samples reaching to high concentration, for which we should sample less than 0.5 \(\mu L\) have been diluted 2 to 4 times.
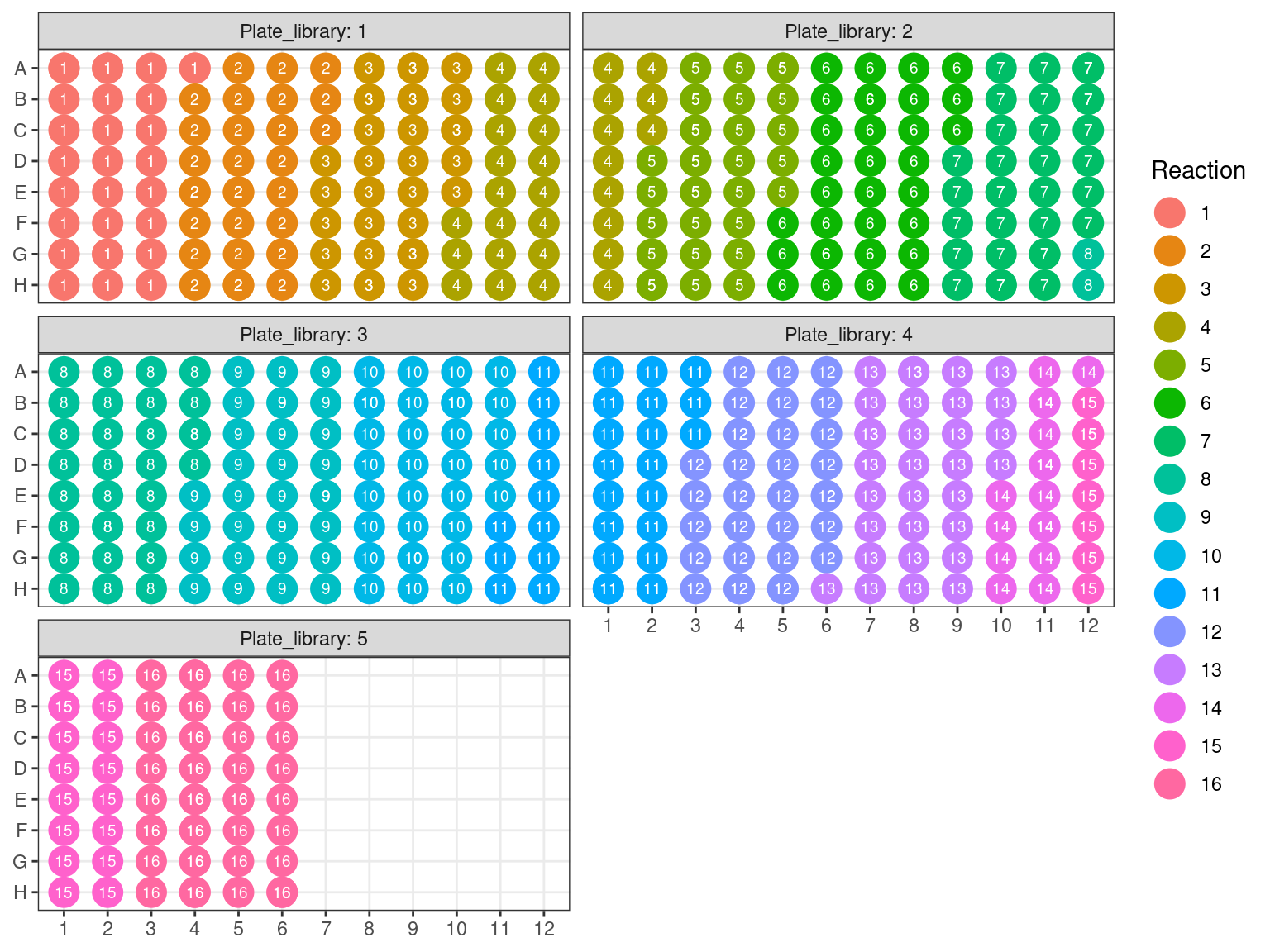
Figure 3.21: Sample reaction tube per plate.
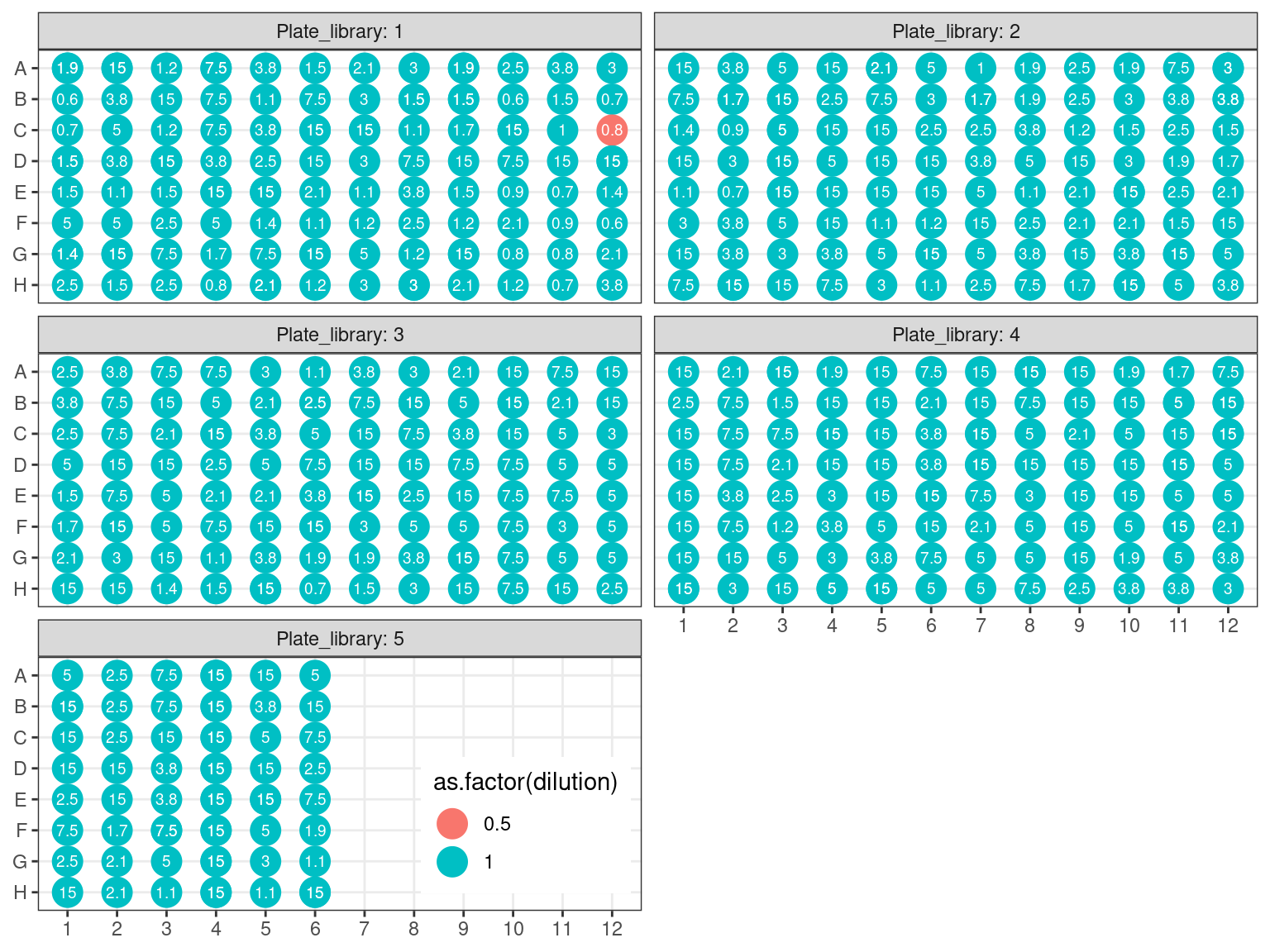
Figure 3.22: Sample reaction volume per plate.
3.4.7 Purification & Concentration

Figure 3.23: DNA content of library pools assessed by NanoDrop.
3.4.8 Size assessment
We had a heterogeneity of fragment size distribution among pools with a large spectrum (Fig. 3.24). We used a TapeStation to select fragments between 330 and 700 bp.
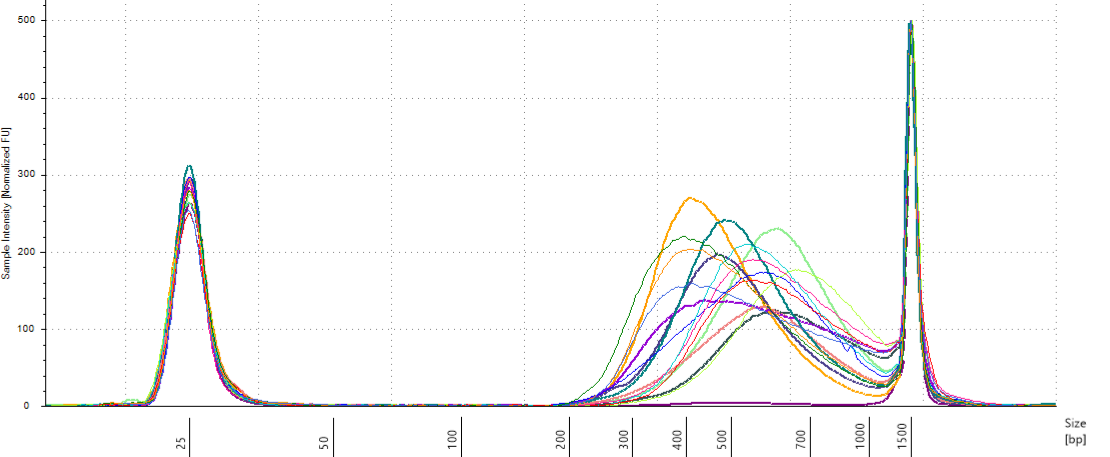
Figure 3.24: Pools size assessment.
3.4.9 Size selection
We did pools of pools for the size selection with Pippin (Fig. 3.25), resulting in \(22*4=88 \mu L\) per pool. But the Pippin used 30 \(\mu L\) and we wanted to do two reactions of Pippin per pool. So we reduced pool volume to 60 \(\mu L\) per pool with the speed vac. Then we used Pippin with a repeat of the 4 pools with 30 \(\mu L\) per pool. We used Pippin to filter fragments between 330 and 750 bp. After the Pippin, we cleaned the samples with 1.8X PGTB Beads from Batch J, and assessed their concentration with QuBIT and their fragment size distribution with TapeStation. We obtained between 180 and 280 ng of DNA (Table 3.4), with fragments distributed between 300 and 700 bp (Fig. 3.26).

Figure 3.25: Pool of reactions.
| Pool | Repetition | Volume (\(\mu L\)) | Concentration (\(ng. \mu L^{-1}\)) | DNA (\(ng\)) | DNA origin (\(ng\)) | Loss factor |
|---|---|---|---|---|---|---|
| 1 | 1 | 37 | 4.94 | 182.78 | 874.0 | 5 |
| 2 | 1 | 37 | 5.33 | 197.21 | 489.0 | 2 |
| 3 | 1 | 37 | 7.38 | 273.06 | 588.5 | 2 |
| 4 | 1 | 37 | 3.98 | 147.26 | 514.0 | 3 |
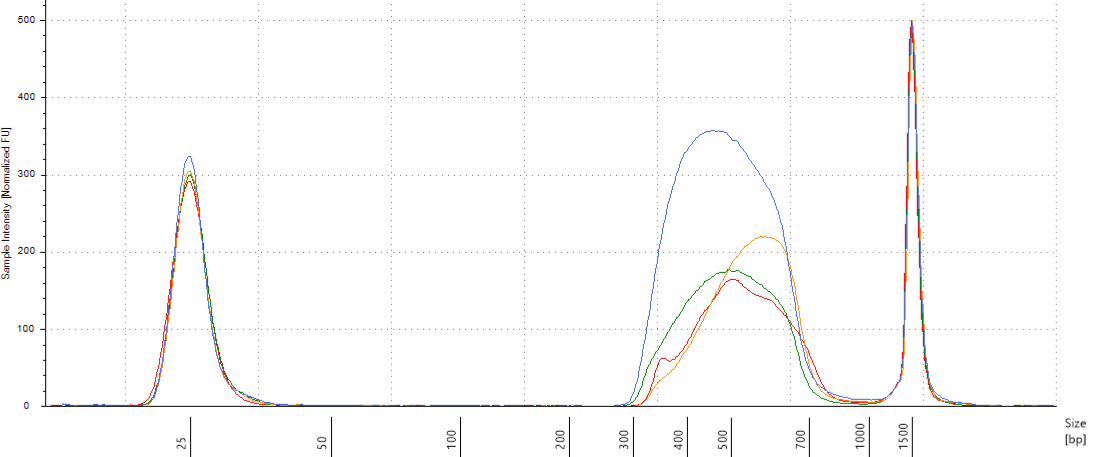
Figure 3.26: Size selected pools assessment.
3.4.10 Capture
We split the 4 pools in 16 reactions (4 replicate capture reactions for each pool) and conducted the capture following ArborScience protocol. After amplification we obtained between 227 and 987 ng of DNA per pool assessed by Qubit (with the four replicates summed, Table 3.5). We then pooled back the capture reactions, assessed their concentration by qPCR and adjusted final samples for sequencing by an equimolar pooling Pools 1 and 2, and 3 and 4 together. We thus obtained 22 \(\mu L\) of Lane 1 at \(7.19~nM\) and 19 \(\mu L\) of Lane 2 at \(10.18~nM\) (see google sheets for more details). The material has been sent to the Genotoul Get team for sequencing on an Illumina HiSeq 3000 on two lanes of pair-ends 150 bp sequences.
| Reaction | Pool | Concentration (\(ng. \mu L^{-1}\)) | DNA (\(ng\)) | DNA pool (\(ng\)) |
|---|---|---|---|---|
| 1 | 1 | 11.300 | 440.700 | 957.450 |
| 2 | 1 | 5.850 | 228.150 | 957.450 |
| 3 | 1 | 5.500 | 214.500 | 957.450 |
| 4 | 1 | 1.900 | 74.100 | 957.450 |
| 5 | 2 | 1.250 | 48.750 | 242.775 |
| 6 | 2 | 1.075 | 41.925 | 242.775 |
| 7 | 2 | 2.350 | 91.650 | 242.775 |
| 8 | 2 | 1.550 | 60.450 | 242.775 |
| 9 | 3 | 7.350 | 286.650 | 986.700 |
| 10 | 3 | 5.650 | 220.350 | 986.700 |
| 11 | 3 | 5.800 | 226.200 | 986.700 |
| 12 | 3 | 6.500 | 253.500 | 986.700 |
| 13 | 4 | 1.380 | 53.820 | 227.955 |
| 14 | 4 | 1.095 | 42.705 | 227.955 |
| 15 | 4 | 1.935 | 75.465 | 227.955 |
| 16 | 4 | 1.435 | 55.965 | 227.955 |
\[ C~in~nM = \frac{C~in~ng/\mu L}{660 .average~fragment~size}.10^6\]
Dilution for qPCR (1 pM) Dilute in cascade your samples from 20.4 - 4.9 nM to almost 1 pM. So we need a 10 000 times dilution. We will do 4 1:10 dilutions with \(1 \mu L\) of sample in \(9 \mu L\) of \(H_2O~milliQ\). Change of tips for every step and better use pipette in the middle of their range than in their extreme (e.g. for \(100 \mu L\) better use a \(200 \mu L\) than a \(100 \mu L\) pipette).
References
Doyle, J. & Doyle, J. (1987). Genomic plant DNA preparation from fresh tissue-CTAB method. Phytochem Bull, 19, 11–15.